Partitioning solutions
Why partitioning ?
It is a technique to physically distribute the data into separate data stores to improve scalability , reduce contention and optimize performance.Case Study 2 : Online food delivery
All the orders that the company receives gets stored in the transactional SQL server. Customer needs to be authenticated to place the order. There is a FTP server which collects invoice PDS and mail them to the customer and analytics team. This architecture is chosen to have faster transactions and maintain consistency. But, the business analytics team is having difficulties to run the historical queries Because- They queries on OLTP system are running for a longer duration
- Also there are some columns with PII data which the organization doesn’t want to show to the business analytics team.
Partitioning strategy
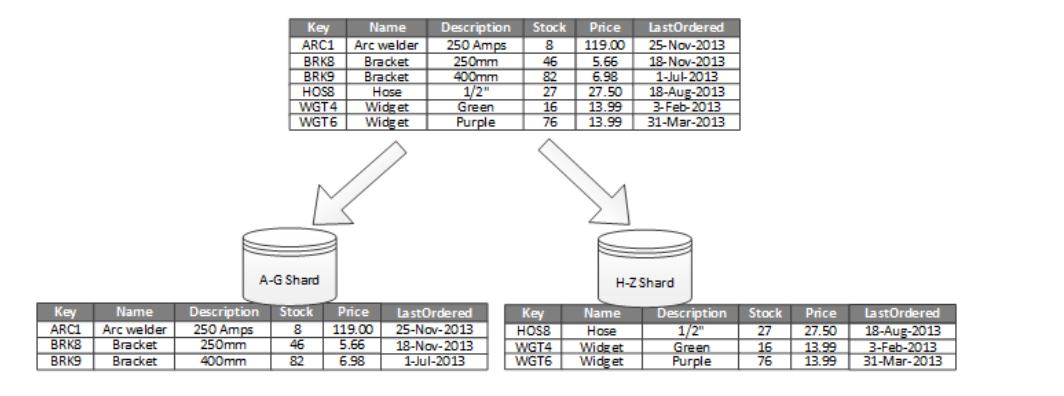
Horizontal Partitioning :
→ Also known as sharding.
→ In this partition, every partition is a separate data store
→ But all the partitions has same schema
→ Each partition is called a shard, which holds a subset of data.
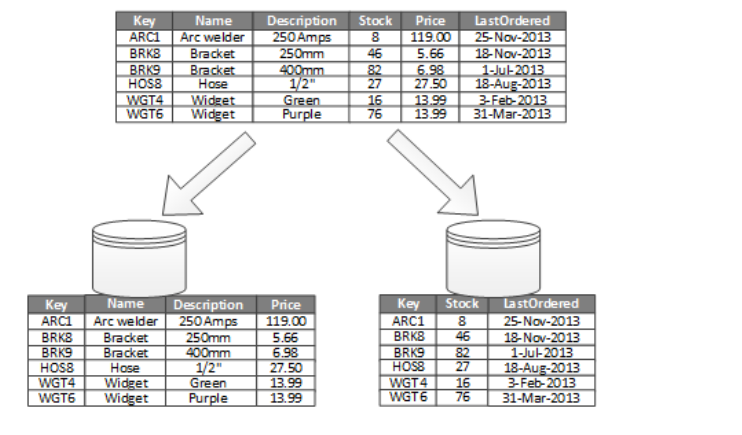
Vertical Partitioning :
→ Each partitioning, each partition holds a subset of fields .
→ Vertical partitioning helps separate the PII columns and speed up the query by setting up the indexes on the different partitions.
Functional Partitioning :
→ Refers to separate data from different domains into different physical nodes to ensure better isolation and performance. .

Partitioning will gives us
→ Scalability
→ performance
→ Availability
Pain points
→ The sharding key we chose should have high cardinality.
→ If we choose a boolean key which just has two states , then it doesn’t matter if we have 10 nodes in the cluster, data will be partitioned into two nodes only.
→ If we chose a date column as partitioning column but downsides of that is,records with current date will go to the same partition , that will cause contention.
→ if the records date got updated with the current date, records shuffling will happen which will affect the database performance.
→ If we choose a column which has too much cardinality , that will cause too many partitions.
Good partitioning key : points
Enough cardinality
Field should not require reshuffling
Frequency of values should be even
Azure partitioning strategies
Hash distributed tables : , a hash function on the key decides the partition that records will be placed. Used when data is greater than 2GB.
Round robin distribution: distributes the rows equally to all the partitions in a round robin fashion. This will be used if there is no good column to distribute.
Partitioning files in Azure Data Lake Gen2
Represent the folder structure in such a way that it represents partitions. Eg: Date wise partitions